Advantages of Pandas Library for Data Analysis Sujeet Pillai February 16, 2023
What is Pandas library?
Pandas is a general-purpose Python library for data analysis and manipulation, including data processing, analyzing, filtering, and aggregation. Pandas library is used in almost any process of extracting information from data using code. The name “Pandas” refers to both “Panel Data” and “Python Data Analysis” and was coined in 2008 by Wes McKinney. Pandas library is a fast, powerful, flexible, and easy-to-use open-source data analysis and manipulation tool built on top of Python programming language. Pandas library can easily manipulate the data and conduct data science analysis operations. It was first released in 2009 and has since grown in popularity as a tool for performing data analysis operations. Pandas are an essential component of the data science life cycle. Along with NumPy in matplotlib, it is the most popular and widely used Python library for data science.
Advantages of Pandas Library for data analysis-
1. Enhanced data analysis
Pandas greatly simplify data analysis and statistical computations, making life easier for data analysts, scientists, and developers. In addition to its stat deduction power, it’s also ideal for transforming raw data into an actionable form. It can clean up messy datasets and organize multiple variables by creating powerful visualizations. Plus, Pandas library accelerates your workflow when dealing with large datasets compared to other Python libraries.
2. Easy to Use and Readable
Pandas have a straightforward and intuitive syntax that is simple enough for beginners to grasp. The library provides a range of functions that can be easily chained together to perform complex data analysis tasks, making writing efficient and making code easy to read. Pandas library can perform operations on data with few lines of code. It saves time and prioritizes creating efficient algorithms for data analysis compared to Python, which takes a lot of time.
For example-
To read a CSV file into a Pandas DataFrame, you can simply use the read_csv() function:
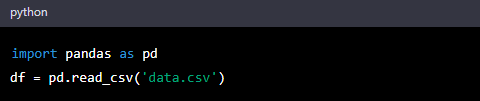
To write a Pandas DataFrame to a CSV file, you can use the to_csv() function:

3. High Performance with Large Datasets
Pandas library can handle large datasets efficiently, even with limited memory resources. It does this by using techniques such as lazy evaluation, which only loads data into memory when needed, and compressing data where possible. Pandas library uses vectorized operations, which enables them to perform computations on entire arrays of data in a single operation. This is much faster than performing computations on individual elements. Furthermore, Pandas also support parallel processing, which allows them to distribute processing across multiple cores or processors. This helps to speed up your computation time, especially for large datasets.
4. Integrates seamlessly with other Libraries
Pandas library integrates easily with other popular libraries in the Python ecosystem, such as NumPy and Matplotlib. This makes using them together for data analysis incredibly streamlined, allowing you to quickly and ably perform powerful data analysis without needing to learn a whole new library. With Pandas, you can use it to wrangle the data into the format you need before accessing the plotting or numerical capabilities of other libraries like PyTorch.
5. Robust Graphical Support for Better Insights
Pandas library makes visualizing your data a breeze! With the matplotlib library, you can access all kinds of graphs and charts to display your data in an easy-to-digest format. From bar plots to pie charts, scatter plots to histograms, Pandas can create informative yet visually appealing graphics. Using the power of basic statistical mechanics, experienced analysts and marketers can easily glean valuable insights from these charts while allowing newcomers to experiment with data without being overwhelmed by the details.
6. Faster Processing and Reporting
Pandas library is built on NumPy, a fast and efficient numerical computing library for Python. This means that Pandas can use NumPy’s array-oriented computing capabilities to perform operations on large datasets in a highly optimized manner. Further, Pandas library provides a wide range of data manipulation and transformation functions that enable analysts to quickly clean and transform data to suit their needs. For example, it provides functions for filtering, sorting, grouping, and aggregating data, which can be performed promptly. Whether you need to quickly process and report on large datasets or crunch numbers in the background, Pandas can do it faster than other libraries.
7. Easier Data Cleaning and Wrangling
Pandas library makes data wrangling, cleaning, and pre-processing easier. Thanks to its inbuilt methods, you can effortlessly avoid irritating white spaces or jumbled string outlines while dealing with datasets. Its sophisticated string manipulation helps cut down development time and increase the overall performance of applications. Alone, these features make Pandas an absolute hidden gem for data analysis.
8. Analyze Unstructured and Tabular Data
Pandas library simplifies data visualization, even with unstructured data like text, images, and videos. It can extract meaningful information from them through text mining and sentiment analysis. For structured data like spreadsheets or databases, Pandas provide powerful tools for filtering, grouping, aggregating, and joining data. It can read data from various files such as Excel, CSV, or SQL formats and perform complex analyses and visualizations.
9. Handles missing data well
Pandas can help in data alignment and handling missing values from the data. By default, it sets any null or missing data to NaN, helping you quickly identify and remove unnecessary information. Pandas library also provides methods such as fillna() to help you replace the missing values with more accurate and useful data for downstream analysis. With this feature, handling corrupt and incomplete datasets is made much easier. It can detect missing values and enable us to drop a column or a row with dropna() or fill it with a constant value.
Conclusion-
From learning data structure and data manipulation to powerful data analysis algorithms, Pandas library is the best for leveraging the power of Python in data analysis. With its array-oriented approach, intuitive commands, and a plethora of features, Pandas simplifies and speeds up discovering insights from your data. With its user-friendly interface and extensive documentation, Pandas library is easy to learn and use for both beginners and advanced users. Whether working with spreadsheets, databases, text, images, or videos, Pandas can help you gain valuable insights from your data and make informed decisions.


 What Is Python Used For? A step-by-step guide for Beginners
What Is Python Used For? A step-by-step guide for Beginners



 Over the past few years, python has grown into a serious scientific computing language. This owes itself to several mathematical packages like NumPy, scipy, and pandas maturing and being trusted by the scientific community. These packages and the inherent simplicity of python had a democratizing effect on the ability to perform complex mathematical modeling without expensive proprietary software.
Over the past few years, python has grown into a serious scientific computing language. This owes itself to several mathematical packages like NumPy, scipy, and pandas maturing and being trusted by the scientific community. These packages and the inherent simplicity of python had a democratizing effect on the ability to perform complex mathematical modeling without expensive proprietary software.

